

Avec l’essor de grands modèles de langage comme ChatGPT, de plus en plus d’entreprises commencent à affirmer que leurs modèles sont capables de « raisonner », c’est-à-dire d’extrapoler à partir de leurs connaissances pour produire des conclusions valides et logiquement solides à un problème complètement nouveau.
Mais une nouvelle étude repérée par Ars Technica montre de manière flagrante qu’il est encore bien trop tôt pour parler de réel » raisonnement « , et que même les meilleurs modèles actuels ont tendance à s’effondrer de façon spectaculaire lorsqu’ils sont confrontés à des pièges triviaux.
Un repère procédural pour pimenter l’évaluation
Pour le démontrer, les auteurs de cette étude, six ingénieurs Apple, se sont appuyés sur GSM8Kun ensemble de données composé de 8 000 problèmes mathématiques de niveau primaire. Il s’agit d’un benchmark souvent utilisé par les développeurs pour illustrer les soi-disant capacités de « raisonnement » de leurs modèles. Par exemple, la première version de GPT-4 a obtenu un score de 92 % sur ce benchmark, et OpenAI l’a présenté comme un « preuve d’un raisonnement mathématique et de capacités supérieures en résolution de problèmes « .
Le problème est que ce type de benchmark n’est pas très pertinent en pratique. Dans de nombreux cas, les questions et réponses ont été directement intégrées dans les données de formation, de sorte que les modèles peuvent immédiatement donner la bonne réponse sans avoir besoin de raisonner.
Les chercheurs d’Apple ont donc décidé de créer une variante plus rigoureuse du GSMK8, appelée Symbole GSM. La grande différence est que ce dernier est un repère procédural, dynamique, qui comporte une certaine variabilité. Au lieu de fournir directement les déclarations telles quelles aux modèles, l’équipe a créé un programme simple qui permet de remplacer certains éléments par des valeurs différentes. Par exemple, une question sur le temps qu’il faut à un pâtissier pour préparer 30 gâteaux pourrait se transformer en une question sur un mécanicien cherchant à réparer 15 voitures.


Il est important de noter que les chercheurs ont veillé très soigneusement à ce que ces changements n’affectent pas la nature du raisonnement requis ni la difficulté. Exactement le même problème après le changement, juste déguisé différemment. Pour reprendre l’exemple ci-dessus, il faut toujours multiplier le nombre de produits par une unité de temps ; le fait que la déclaration parle de préparer un dessert ou de réparer un véhicule ne change absolument rien à la façon dont le problème est abordé. En théorie, si les LLM étaient réellement capables de raisonner, ils auraient donc dû obtenir des scores identiques sur GSKM8 et sur GSM-Symbolic, plus ou moins.
Pièges logiques triviaux mais dévastateurs
Mais comme vous pouvez probablement l’imaginer, c’est tout le contraire qui s’est produit ! Les chercheurs ont constaté que tous les modèles testés, sans exception, obtenaient des scores nettement inférieurs au GSM-Symbolic. Certains étaient totalement désorientés par ces changements mineurs. Mistral-7b-it-v0.1 a par exemple vu son score chuter de 9,2% sur GSM-Symbolic.

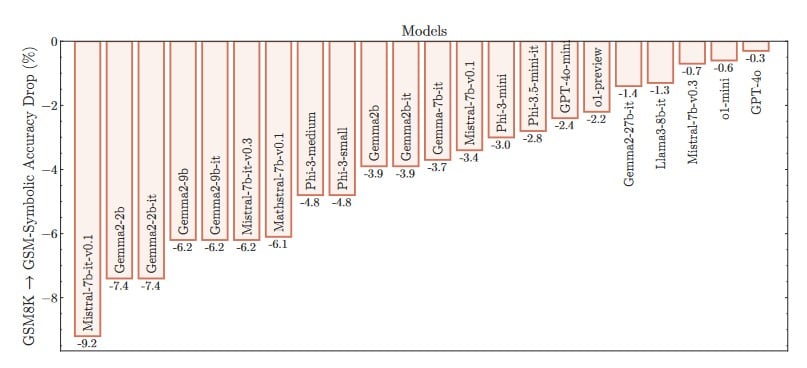
Et ce ne sont pas les seules données qui illustrent de réelles lacunes. Les auteurs ont également noté une très grande variabilité d’un test à l’autre. Plus de 50 itérations consécutives de GSM-Symbolic, avec des valeurs différentes à chaque fois mais toujours le même problème de base, les scores peuvent varier d’environ 15 % — un nombre assez énorme dans ce contexte.
En revanche, certains modèles comme le GPT-4o s’en sortent relativement bien. Le produit d’OpenAI affiche une baisse de 0,3% d’un benchmark à l’autre, ce qui semble à première vue presque négligeable. Peut-on dès lors considérer qu’il est effectivement capable de raisonner logiquement ?
Pour le vérifier, les chercheurs ont relancé leur expérience en introduisant de nouveaux pièges. Plus précisément, ils ont ajouté « déclarations apparemment pertinentes mais en fait sans conséquence » aux déclarations. Par exemple, à une question sur le nombre de kiwis récoltés sur plusieurs jours, les chercheurs ont précisé que certains fruits étaient un peu plus petits que d’autres. Puisque la réponse ne dépend absolument pas de la taille ou du poids des kiwis, un adulte comprendrait vite que cette précision ne doit pas être prise en compte.
Un jeune enfant serait-il tombé dans le panneau ? Peut-être, et il aurait été intéressant de faire une étude comparative en classe pour en juger. Mais ce qui est sûr, c’est que les LLM se sont tous laissé berner. Ces détournements, pourtant basiques, leur faisaient complètement perdre le contrôle.conduisant à ce que les chercheurs décrivent comme « baisses de performances catastrophiques « . GPT-4o, qui avait bien réussi au test précédent, a vu son score chuter de 32%. D’autres se sont complètement effondrés, comme Phi-3-mini-128k-instruct et son affligeant -65,7% de précision…


Pas de véritable raisonnement parmi les LLM
Pour les auteurs de l’étude, ces chiffres pointent vers un « défaut critique « . Cela suggère qu’il y a de vrais problèmes fondamentaux dans le processus de raisonnement » qui ne peut être résolu simplement en affinant les poids et les biais qui conditionnent le fonctionnement des modèles. Pour faire mieux, il faudrait repartir de zéro avec une architecture complètement différente.
Sur la base de ces résultats très éloquents, les chercheurs affirment que « Les LLM actuels ne sont pas capables d’un véritable raisonnement logique « . Ils essaient en fait de masquer cet écart en » essayer de reproduire les étapes de raisonnement liées à d’autres problèmes présents dans leurs données d’entraînement « . Autrement dit, ils se comportent un peu comme un jeune étudiant qui aurait appris son cahier par cœur ; ils peuvent obtenir une excellente note à condition de rester en terrain connu, mais l’illusion s’effondre immédiatement dès qu’ils sont sortis de leur zone de confort, puisqu’ils n’ont finalement aucun n’a rien compris à la logique sous-jacente.
C’est une conclusion qui ne surprendra probablement personne. Après tout, ces LLM sont essentiellement des systèmes prédictifs très efficaces pour reconnaître des modèles qui nous échappent. En fin de compte, ils restent machines à deviner. Bien sûr, ils le font souvent de manière très efficace, mais cela reste un approche fondamentalement différente du véritable raisonnement construit.
C’est loin d’être la première fois que les spécialistes rejettent l’idée selon laquelle les LLM seraient dotés de raison, mais cette étude en est une bonne démonstration. l’immense fossé qui sépare les revendications des entreprises et la réalité concrète. N’en déplaise à Sam Altman, PDG d’OpenAI, l’intelligence artificielle générale (AGI) qu’il évoque si souvent est encore très loin d’être à la portée des modèles actuels.
Vers un grand changement de paradigme ?
Plus largement, on peut légitimement s’interroger sur les limites des LLM actuels. Les experts affirment depuis longtemps que l’approche actuelle se heurtera probablement à un mur, en partie à cause d’un processus de formation inapproprié. Les humains en sont un bon exemple.
Nous savons très bien qu’ingérer des informations brutes pour en extraire des modèles récurrents, comme le font les LLM, ne suffit pas.. Si le programme scolaire des enfants consistait simplement à mémoriser l’intégralité du dictionnaire et des millions de pages de tables d’addition et de multiplication, ils souffriraient probablement des mêmes lacunes logiques que les modèles d’IA ! S’ils sont capables de construire une véritable intelligence au cours de leur vie, c’est avant tout parce que nous leur inculquons notions plus abstraites et conceptuellessur lesquels ils pourront compter plus tard.
Le défi est de trouver un moyen de faire de même avec les modèles d’IA. Mais il s’agit d’un énorme défi technique qui impliquera sans aucun doute un changement de paradigme majeur à moyen voire long terme.
Il conviendra donc de suivre les progrès des chercheurs en IA, car cette révolution technologique ne fait que commencer. Mais en même temps, croisons les doigts pour que les entreprises cessent de promouvoir ces termes trompeurs, qui peuvent amener les internautes moins férus de technologie à penser qu’ils ont déjà affaire à des entités conscientes et véritablement intelligentes.
Le texte de l’étude est disponible ici.
🟣 Pour ne manquer aucune actualité du Journal du Geek, abonnez-vous sur Google News. Et si vous nous aimez, nous avons une newsletter tous les matins.